
A Coordinated Electric System Interconnection Review—the utility’s deep-dive on technical and cost impacts of your project.
Challenge: Frequent false tripping using conventional electromechanical relays
Solution: SEL-487E integration with multi-terminal differential protection and dynamic inrush restraint
Result: 90% reduction in false trips, saving over $250,000 in downtime
Beyond the Megawatt: How NERC Is Rethinking What Makes a Load "Large

jun 7, 2026 | Blog
For most of grid history, a large load was just a big version of a familiar thing — a steel mill, a refinery, a pump station. It drew a lot of power, but it behaved the way planners expected: relatively steady, mechanically governed, and predictable enough to model with decades-old techniques. That assumption is breaking down. In July 2025, NERC's Large Loads Task Force (LLTF) published its first major output, a white paper characterizing the new generation of large loads — AI data centers, cryptocurrency mines, hydrogen electrolyzers, and a widening class of electrified industrial facilities — and cataloguing the reliability risks they pose to the bulk power system (BPS).
The paper's central argument is one every developer, utility planner, and interconnection engineer should internalize: peak demand alone is no longer a sufficient way to describe a large load. A 100 MW facility that ramps from near-zero to full output in under a second, trips itself off-line during a voltage sag, and injects subsynchronous oscillations is a fundamentally different reliability object than a 100 MW facility that sits at a flat load factor all year. The megawatt number is the same. The risk profile is not.
This post walks through what the white paper actually says — how it defines and categorizes these loads, the physical mechanisms by which they stress the grid, and what the documented field events tell us about where the real exposure lies.
A definition built around behavior, not size
NERC's LLTF deliberately declined to anchor its definition to a megawatt threshold. Instead, it defined a large load as any commercial or industrial load facility — or aggregation of facilities at a single site behind one or more points of interconnection — that can pose reliability risks to the BPS because of its demand, operational characteristics, or other factors. The named examples span data centers, crypto mining, hydrogen electrolyzers, manufacturing plants, and arc furnaces.
The refusal to set a single number is a feature, not an omission. An informal task force survey landed on roughly 50–75 MW as where "large" begins, with 75 MW the most common single answer — but the same survey surfaced the obvious problem: a 20 MW site is enormous on a distribution feeder and trivial at transmission voltage. A fixed threshold also invites gaming, where developers size projects just under the line to dodge scrutiny. The white paper's position is that size matters but is too blunt to stand alone; the characteristics that actually drive risk are demand profile, ramp rate, load predictability, voltage sensitivity (ride-through), power-electronic content, internal segmentation, and how fast the project wants to interconnect.
The taxonomy: not all "data centers" are the same load
The paper's characterization chapter is worth reading closely because it draws distinctions that interconnection studies frequently blur.
Traditional data centers are the legacy cloud and enterprise facilities — historically under about 30 MW, redundancy-obsessed, optimized for uptime (Tier IV facilities target availability above 99.995%). Electrically, they behave relatively benignly: high load factor, limited variability, mostly static consumption.
AI training facilities are the disruptive newcomer. Training executes across large GPU clusters whose power draw swings violently with the workload. The white paper documents a 50 MW block of a 200 MW training facility ramping at 1.9 per-unit per second for roughly 250 milliseconds, with transitions between training and checkpoint-saving happening in under a second. Critically, many AI training designs forgo UPS protection on the IT equipment entirely — they rely on a checkpoint-and-restore scheme instead, which means the facility is willing to drop load rather than ride through a disturbance.
AI inference facilities use similar high-power GPUs but, with current methods, don't exhibit the violent training ramps. Several industry voices expect inference to eventually dominate energy consumption as deployment scales.
Cryptocurrency mining runs ASIC hardware at comparatively stable power, driven by internal computation rather than external demand — which makes miners unusually price-responsive and flexible, but also concentrated and fast to curtail.
Hydrogen electrolyzer plants are perhaps the most power-electronic-heavy of all: surveys cited in the paper put converter-based load above 85% of facility consumption, with individual electrolyzers at 5–10 MW and total facilities potentially reaching multi-gigawatt scale.
What ties the disruptive categories together is that they are power electronic loads (PELs) — governed by software-driven converters rather than the mechanical inertia of motor loads. That single architectural fact is the root of most of the risks that follow.
The scale problem, in two numbers
Two figures from the paper frame the urgency. Data centers may reach as much as 12% of total U.S. electricity consumption by 2028, up from 4.4% in 2023. And as of late April 2025, ERCOT reported roughly 136 GW of
large load in its interconnection queue against a system whose historic peak is about 85 GW. Even discounting heavily for projects that never materialize — and "location shopping," where developers file in multiple regions simultaneously, makes the queue notoriously unreliable as a forecast — the magnitude dwarfs anything planners have absorbed before.
Where the risk actually lives
The white paper organizes risks across planning, operations, stability, power quality, security, and restoration, and — importantly — prioritizes them. The high-priority cluster is resource adequacy, balancing and reserves, and a set of stability problems (ride-through, voltage stability, angular stability, and oscillations). Here's the engineering substance behind the headline categories.
Ride-through and load loss.
The defining field events of this era are large-load drops, not surges. On July 10, 2024, a lightning arrestor failure on a 230 kV line in the Eastern Interconnection produced repeated faults and voltage depressions of 0.25–0.40 per unit. Roughly 1,500 MW of voltage-sensitive load — mostly data centers — disconnected, not because utility breakers tripped, but because customer-side protection switched the facilities to backup power. Frequency rose to 60.053 Hz and took about four minutes to settle. The Eastern Interconnection is the most inertia-rich on the continent; the paper notes a comparable loss in ERCOT could swing frequency by around 235 mHz. The lesson isn't that 1,500 MW is catastrophic — it's that this behavior was unmodeled and unanticipated, which means the studies protecting the grid had a blind spot.
Balancing and reserves.
PELs shift consumption faster than conventional generators can ramp. The paper documents a data center dropping from about 450 MW to 40 MW in 36 seconds, and a crypto facility shedding 298 MW in 25 seconds while exhibiting ~25 MW peak-to-peak oscillations after a telecom-driven control failure. At the aggregate level, AI training at the largest clusters can swing tens of megawatts per minute, and the paper flags that this directly threatens balancing-authority metrics like CPS1 and BAAL under BAL-001 — fast, unpredictable ramps can outrun a fleet's regulation capability and deplete reserves.
Rotor angle stability.
This is the subtlest and, arguably, most underappreciated mechanism. When a large load trips during or after a fault, it removes the "braking" load that would normally help decelerating-then-accelerating generators recover synchronism. The paper shows simulations where generators near a tripped data center lose angular stability within seconds. There's a second-order effect too: because PELs often operate at near-unity displacement power factor with filters that produce reactive power, they can appear as capacitive loads. That improves voltage regulation but forces nearby synchronous generators to absorb reactive power, reducing their angular stability margin — and if that reactive behavior isn't captured in studies, the available margin is silently overestimated.
Converter-driven and resonance stability.
Because these loads are converter-dominated, they can exhibit the same instabilities as inverter-based generation — including weak-grid instability where phase-locked loops go unstable at low short-circuit ratios (around 2 or below). The paper points to the 2019 trip of an 800 MW offshore wind plant in Great Britain as the cautionary analogue, an event that contributed to an outage affecting over a million customers.
Forced oscillations.
Large loads can be oscillation sources, not just amplifiers. AI training produces periodic, repetitive load profiles; arc furnaces produce subsynchronous content as a byproduct of arcing. When a load's oscillation frequency happens to align with a turbine's torsional mode or an interarea mode, the consequences scale up dramatically — the paper cites a 2019 Florida steam turbine that produced a 200 MW, 0.25 Hz oscillation that propagated across the Eastern Interconnection and was still measurable (~50 MW) in New England 18 minutes later. A 2023 Midwest data center inadvertently produced a 1 Hz forced oscillation that stimulated an 11 Hz ringdown, and Dominion has observed oscillations near 14.7 Hz arising from data center UPS input interactions.
Power quality.
PEL-heavy facilities inject harmonics from both IT equipment (UPS, power supplies) and cooling (variable speed drives), and variable load profiles produce flicker — a problem that compounds when these loads concentrate in areas where background flicker is already near limits. The paper shows measured cases where harmonic mitigation cut voltage distortion substantially, underscoring that these are solvable with proper filtering — if the problem is identified in study.
Restoration and load shed.
Large loads complicate the last lines of defense. They inflate UFLS obligations (potentially beyond what the local distribution system can satisfy, pushing UFLS to the transmission level), and their internal segmentation makes blackstart restoration riskier — restoring too much load too fast can crash a fragile island, and a restored large load that ramps up without operator instruction can do the same.
The thread running through all of it: observability
If there's a single root cause beneath the catalogue, it's that these loads are largely invisible to the people responsible for grid reliability. Large load owners are generally not NERC-registered entities, so they aren't bound by Reliability Standards, aren't required to share dynamic models or protection settings, and in several documented events were difficult to even get information from after the fact. Few have PMUs or high-speed recording. Operators frequently don't know the triggers — price, emissions, currency — that cause a facility to shift hundreds of megawatts. You cannot study, forecast, or mitigate what you cannot see, and the white paper's stability chapter repeatedly returns to the same conclusion: the risk is less that these loads behave badly and more that they behave in ways the models never captured.
What this means for projects on the ground
NERC's framing has direct consequences for how large-load interconnection should be approached. The characteristics that belong in an interconnection request now extend well past peak MW: ramp rate, ride-through and voltage/frequency trip settings, internal protection and backup-transfer logic, reactive power behavior, harmonic signature, oscillation content, and segmentation for restoration. Dynamic models that actually represent the converter controls — not a generic static load — are becoming the difference between a study that protects the system and one that flatters it. And because so much of the risk is local (short-circuit ratio, nearby generation, reactive resources) while some is interconnection-wide (inertia, interarea modes), the same facility can be benign in one location and hazardous in another.
The task force's roadmap makes clear this is the opening move, not the conclusion: a forthcoming gap-analysis white paper will identify where existing standards and practices fall short, followed by a reliability guideline on mitigations and interconnection procedures. For anyone planning, studying, or building large loads, the strategic takeaway is to stop treating these facilities as oversized conventional loads and start treating them as what they are — fast, converter-driven, partially-hidden dynamic devices that have to earn their place in the study models before they earn their place on the grid.
Case Studies
Case Study 1 — The xxxxx MW That Wasn't Supposed to Move
Situation.
A high-voltage transmission line in a large, inertia-rich interconnection suffered a hardware failure on a piece of station equipment, producing a sequence of faults over roughly a minute and a half. In the affected region, voltage sagged to between a quarter and 40% of nominal during the disturbances — significant, but the kind of event the system is built to clear and recover from. Conventional generation rode through as designed.
What actually happened.
Across the region, a large fleet of voltage-sensitive computational loads — primarily data centers — responded to the transient voltage dips not by riding through, but by transferring to on-site backup power. Roughly x,x00 MW of demand vanished from the grid almost simultaneously. Notably, the utility breakers serving these facilities never tripped; the disconnection was entirely customer-initiated, driven by internal protection logic configured to protect the facilities' own processes (in several cases, switching to backup after a small number of transient dips within a short window). The sudden generation-load imbalance pushed system frequency above nominal before automatic and governor response pulled it back over a span of minutes.
Engineering takeaways.
Three points stand out. First, the event was a load-loss event, not a generation event, and it was invisible in advance because the customer-side protection behavior was never represented in interconnection or planning studies. Second, the outcome was survivable only because of the interconnection's large inertia base — the same load loss in a smaller, lower-inertia interconnection would have driven a far larger frequency excursion. Third, the loads did not return promptly, which distorted downstream demand forecasts and operational situational awareness for an extended period. The actionable lesson for any large-load interconnection is that ride-through settings and backup-transfer logic must be disclosed, modeled, and studied as first-class parameters — not treated as internal facility details outside the utility's concern.
Case Study 2 — A Telecom Glitch, a xxx MW Drop, and an Oscillation Nobody Ordered
Situation.
A large cryptocurrency mining facility, dense with ASIC hardware and converter-based power delivery, was operating normally when an off-site telecommunications failure disrupted its load-control system.
What actually happened.
Two distinct problems surfaced. First, the control disruption left the facility exhibiting sustained real-power oscillations with a peak-to-peak amplitude on the order of 25 MW — a fixed-source forced oscillation injected directly into the local grid. Second, when the operator instructed the facility to reduce demand, it shed approximately 300 MW in about 25 seconds. Both behaviors are well within the documented capability envelope of converter-dominated loads, which can ramp far faster than synchronous generation can follow.
Engineering takeaways.
This case illustrates two failure modes in one event. The forced oscillation is the quieter danger: had its frequency coincided with a nearby turbine torsional mode or a poorly damped interarea mode, it could have propagated into rotating equipment (accelerating shaft fatigue) or across a wide area, rather than staying local. The 298 MW ramp is the louder danger: a swing of that speed and magnitude, especially if aggregated with similar facilities, can strain regulation reserves and degrade balancing performance. The broader point is that the triggering cause was mundane — a communications fault — and the facility's response was governed by control logic the grid operator had limited visibility into. Robust large-load integration therefore has to account not just for intended operation but for the facility's behavior under its own internal fault and control-loss conditions.
Case Study 3 — When the Load Becomes the Source
Situation.
A large computational facility in a region with substantial data center concentration was operating under normal conditions. Its power delivery architecture included converter-based front-end equipment of the type common to such facilities.
What actually happened.
The facility inadvertently became an oscillation source. Periodic forcing at a roughly one-second interval — produced by the facility's active power electronics — stimulated a natural system mode, with each perturbation producing a well-damped higher-frequency ringdown observable on the surrounding network. Separately, in the same general class of facility, oscillations in the low-tens-of-hertz range have been traced to interactions among the input stages of data center UPS units. Neither behavior was an intended function of the load; both emerged from the collective dynamics of large quantities of converter equipment operating together.
Engineering takeaways.
This case is the clearest illustration of the white paper's core message that these loads are dynamic devices, not passive demand. The oscillatory behavior depends heavily on the internal control algorithms of the power electronics — which vary by vendor and model and are usually protected intellectual property, meaning the data needed to model the risk is precisely the data least likely to be shared. Risk rises when such facilities sit near other oscillation-prone equipment (generators, capacitor banks, other converter concentrations) or connect through weak ties with low short-circuit ratio. Mitigation starts with measurement: phasor and high-speed recording at or near these facilities is often the only way to detect and diagnose the problem, and that capability has to be designed in rather than retrofitted after an event. For developers and utilities alike, the implication is that interconnection study scope for converter-heavy loads should explicitly include resonance, converter-driven, and forced-oscillation screening — categories that simply weren't on the checklist for conventional industrial loads.
FAQ: Emerging Large Loads and Bulk Power System Reliability
Q: What is a "large load" in NERC's framework?
NERC's Large Loads Task Force defines it as any commercial or industrial load facility, or aggregation of facilities at a single site behind one or more points of interconnection, that can pose reliability risks to the bulk power system due to its demand, operational characteristics, or other factors. Examples include data centers, cryptocurrency mining facilities, hydrogen electrolyzers, manufacturing plants, and electric arc furnaces.
Q: Why didn't NERC set a megawatt threshold?
Because size alone is too blunt. A 20 MW site is large on distribution and small at transmission voltage, and a fixed number invites developers to size just beneath it. An informal survey pointed to roughly 50–75 MW as the practical entry point for "large" (75 MW being the most common single answer), but the task force concluded that demand profile, ramp rate, predictability, voltage sensitivity, power-electronic content, and segmentation matter as much as peak demand.
Q: What does "PEL" mean and why does it matter?
PEL stands for power electronic load — a facility whose consumption is governed by software-driven converters rather than the mechanical dynamics of motor loads. PELs can change consumption extremely fast and can interact with grid dynamics in ways traditional loads never did. Most of the novel risks in the white paper trace back to high power-electronic content.
Q: How are the load categories different from one another?
Traditional data centers are uptime-focused, redundant, and relatively static. AI training facilities ramp violently (documented at 1.9 per-unit per second over ~250 ms) and often drop load rather than ride through disturbances. AI inference uses similar GPUs but doesn't show the violent ramps with current methods. Cryptocurrency mines run at stable power but are highly price-flexible. Hydrogen electrolyzer plants are over 85% converter-based load and can scale into the gigawatts.
Q: How fast is large-load growth?
Data centers may reach as much as 12% of U.S. electricity consumption by 2028, up from 4.4% in 2023. As of late April 2025, ERCOT reported roughly 136 GW of large load in its interconnection queue against an 85 GW historic system peak — though queues overstate reality because of cancellations and "location shopping" across regions.
Q: What are the highest-priority risks?
NERC prioritizes resource adequacy (long-term planning), balancing and reserves (operations), and a stability cluster covering ride-through, voltage stability, angular stability, and oscillations.
Q: Why is "ride-through" such a focus?
Because the defining events have been large-load disconnections. In a July 2024 Eastern Interconnection event, repeated faults caused roughly 1,500 MW of voltage-sensitive load — mostly data centers — to switch to backup power and drop off the grid, pushing frequency to 60.053 Hz. The load loss came from customer-side protection, not utility action, and it wasn't represented in the models.
Q: How do large loads threaten balancing and frequency?
They can shift hundreds of megawatts in seconds — faster than generators can ramp. Documented cases include a data center dropping 450 MW to 40 MW in 36 seconds and a crypto facility shedding 298 MW in 25 seconds. Fast, unpredictable ramps can outrun regulation reserves and degrade balancing-authority performance metrics (CPS1, BAAL under BAL-001).
Q: What is the angular (rotor angle) stability concern?
When a large load trips during or after a fault, it removes load that would otherwise help generators recover synchronism, and simulations show nearby generators losing angular stability within seconds. Additionally, many PELs produce reactive power (leading power factor), forcing nearby synchronous generators to absorb reactive power and reducing their stability margin — a margin that gets overestimated if the behavior isn't modeled.
Q: Can large loads cause oscillations themselves?
Yes. AI training produces periodic, repetitive load profiles, and arc furnaces produce subsynchronous content naturally. If a load's oscillation aligns with a turbine torsional mode or an interarea mode, it can propagate widely or fatigue equipment. Documented examples include a 1 Hz data center forced oscillation, ~14.7 Hz oscillations from data center UPS interactions, and an interarea oscillation that spread across the Eastern Interconnection.
Q: What about power quality?
PEL-heavy facilities inject harmonics from both IT and cooling equipment and can cause flicker from variable load profiles, especially where background flicker is already high. These are mitigable with proper filtering — but only if identified during study.
Q: How do large loads affect load shedding and restoration?
They can inflate UFLS obligations beyond what local distribution can supply (potentially requiring transmission-level load in UFLS programs), and their internal segmentation makes blackstart restoration riskier, since restoring too much load too fast can collapse a fragile island.
Q: What is the single biggest underlying problem?
Observability. Large load owners are generally not NERC-registered entities, so they aren't required to share dynamic models, protection settings, or the triggers that cause large consumption shifts. Few have high-speed measurement. You can't study, forecast, or mitigate behavior you can't see.
Q: Are large loads required to provide flexibility?
No. Most request firm service, which obligates the utility to build transmission to serve full peak demand at all times. Voluntary curtailment and demand-response programs exist (and some markets let loads provide ancillary services), but participation is an economic choice, not a requirement.
Q: What comes next from NERC?
This characterization paper is phase one. A gap-analysis white paper will identify where existing standards and practices fall short, followed by a reliability guideline on mitigations and interconnection procedures, plus work items on load modeling, protection-system impacts, and resource-adequacy assessment methods.

About the Author:
Sonny Patel P.E. EC
IEEE Senior Member
In 1995, Sandip (Sonny) R. Patel earned his Electrical Engineering degree from the University of Illinois, specializing in Electrical Engineering . But degrees don’t build legacies—action does. For three decades, he’s been shaping the future of engineering, not just as a licensed Professional Engineer across multiple states (Florida, California, New York, West Virginia, and Minnesota), but as a doer. A builder. A leader. Not just an engineer. A Licensed Electrical Contractor in Florida with an Unlimited EC license. Not just an executive. The founder and CEO of KEENTEL LLC—where expertise meets execution. Three decades. Multiple states. Endless impact.
Services

Let's Discuss Your Project
Let's book a call to discuss your electrical engineering project that we can help you with.
About the Author:
Sonny Patel P.E. EC
IEEE Senior Member
In 1995, Sandip (Sonny) R. Patel earned his Electrical Engineering degree from the University of Illinois, specializing in Electrical Engineering . But degrees don’t build legacies—action does. For three decades, he’s been shaping the future of engineering, not just as a licensed Professional Engineer across multiple states (Florida, California, New York, West Virginia, and Minnesota), but as a doer. A builder. A leader. Not just an engineer. A Licensed Electrical Contractor in Florida with an Unlimited EC license. Not just an executive. The founder and CEO of KEENTEL LLC—where expertise meets execution. Three decades. Multiple states. Endless impact.
Leave a Comment
Thank you for contacting us.
We will get back to you as soon as possible.
We will get back to you as soon as possible.
Oops, there was an error sending your message.
Please try again later.
Please try again later.
Related Posts
By SANDIP R PATEL
•
July 31, 2026
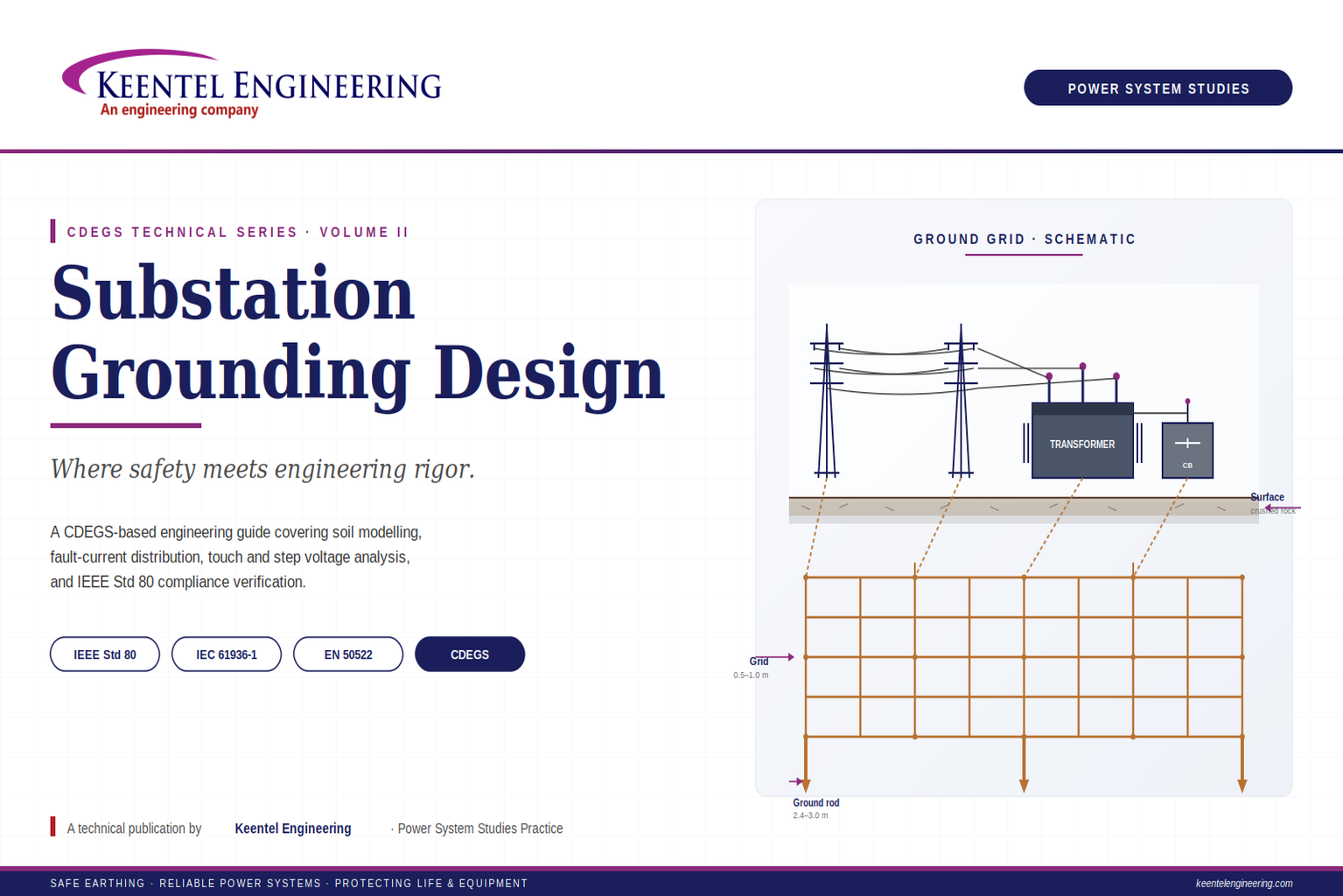
Learn substation grounding design using IEEE Std 80, CDEGS, soil resistivity modeling, touch and step voltage analysis, GPR, and earthing best practices.
By SANDIP R PATEL
•
July 29, 2026
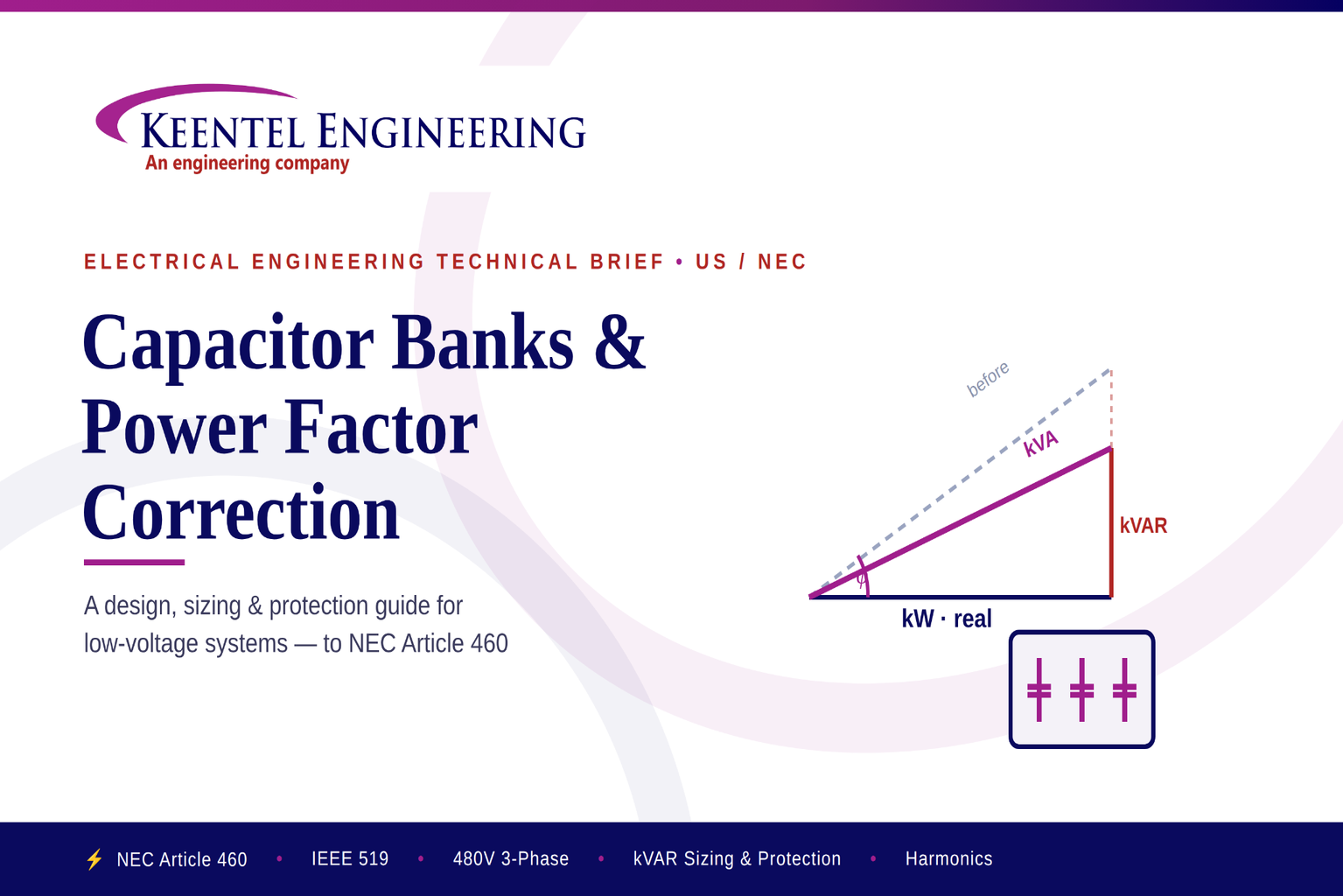
Learn capacitor bank sizing, power factor correction, NEC Article 460 requirements, harmonic mitigation, protection, and installation for industrial power systems.

By SANDIP R PATEL
•
July 29, 2026
Learn the differences between On-Load and Off-Circuit Tap Changers, including OLTC vs OCTC operation, voltage regulation, IEEE standards, maintenance, and transformer selection.

By SANDIP R PATEL
•
July 28, 2026
Learn the differences between the PUCT Generating Capacity Report and ERCOT Form W, including Part A vs Part B, PCLR, WLPUN, BYOG projects, and Batch Zero compliance.

By SANDIP R PATEL
•
July 28, 2026
Learn how PGRR144, Batch Zero, and Batch 1 affect ERCOT large-load interconnections, dynamic model requirements, MQT testing, PERC1, and project readiness.

By SANDIP R PATEL
•
July 28, 2026
ERCOT PCLR Batch Zero large-load interconnection pathway
By SANDIP R PATEL
•
July 27, 2026
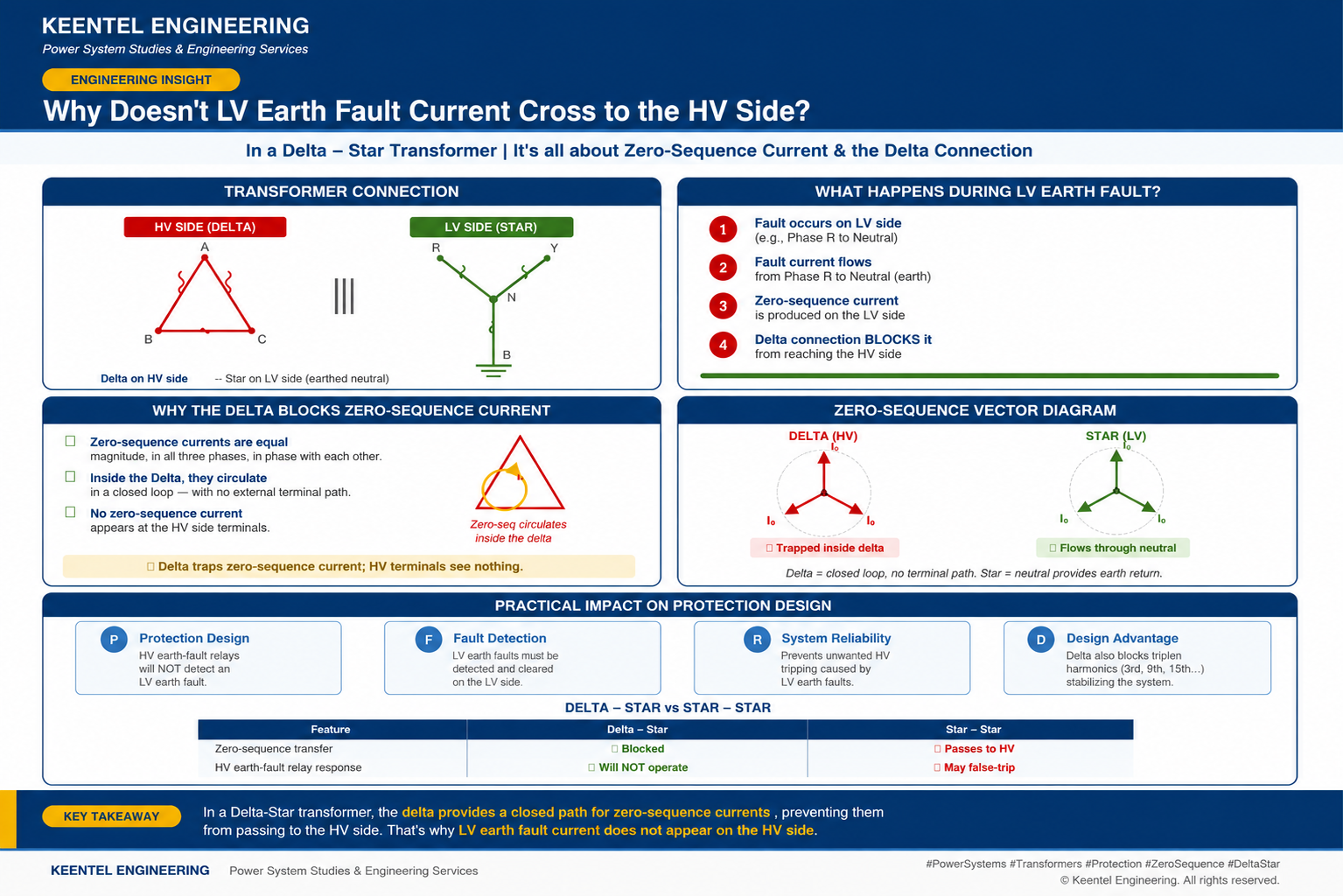
Learn why LV earth-fault current cannot cross a Delta-Star transformer, how zero-sequence current behaves, and what it means for protection design.

By SANDIP R PATEL
•
July 27, 2026
Learn how gas-insulated substations (GIS) improve safety, reliability, and space efficiency with 138 kV design, protection, insulation coordination, and real-world case studies.

By SANDIP R PATEL
•
July 25, 2026
Learn how Class I–IV electrical systems, defence-in-depth, standby and emergency power, DC systems, protection, and load transfer ensure nuclear power plant safety.





